Looking for UMUC Data 620 Assignment 12.1: Text Analysis with Python? Get Assignment Answers on UMUC Data 620 Assignment 12.1. We Provide Australian Assignment Help, Programming Assignment Help & ICT112 Pythong Programming Assignment Help from Masters and PhD Expert at Lowest price?

UMUC Data 620 Assignment 12.1
Given unstructured text data, each student processes the text data and creates valuable business analytics, similar to those in the Elder Research and Jiffy Lube case studies. Each student creates a managerial report identifying the patterns and recommendations uncovered in the data.
Complete instructions may be found below.
Turn in separate files with the following items. Please label each with the TURN IN # statement so we can easily follow it.
| Deliverable | Description | Points |
| TURN IN #1 | Managerial report outlining your findings. Name this file “XXXX-text-analysis” where XXXX is your name. See the Grading rubric in this assignment for more details. | 200 |
| TOTAL | 200 |
- Read the Elder Research and Unilever case studies and note the types of information they were able to extract from the text data. (We don’t quite have that amount of information available, or quite that level of software, so your conclusions won’t be quite as detailed.)
- Elder Research Inc. (2013). Improving customer retention and profitability for a regional provider of wireless services. Retrieved from https://cdn2.hubspot.net/hubfs/2176909/Resources/Elder-Research-Case-Study-Customer-Retention-nTelos.pdf .
- Jiffy Lube Uses Odin Text Software to Increase Revenue.https://greenbookblog.org/2018/01/12/shell-oil-identifying-key-revenue-drivers-in-customer-comment-data/There’s also an interesting interview video here: https://www.youtube.com/embed/2Zxmjir8Zwo?autoplay=1
- These case studies are for inspiration only; there is nothing to turn in from them.
- Choose a readily available text item which recurred over at least three time periods, spaced some distance apart. You want to make sure you have at least several thousand words of text (more than 10 pages) for each time period, and you want something which will change noticeably over that time period. Some options could include:
- The CEO’s letter to shareholders (I do Amazon.com below as an example – you may choose any other company) in three different years; you may want to supplement with additional information from the company if this isn’t long enough.
- The State of the Union Address (or other political speeches) from three different Presidents, such as those from Woodrow Wilson, Lyndon B. Johnson, and Barack Obama
- The State of the State Addresses from any one of our 50 states
- A write up of something technical (like descriptions of Motor Trend’s Car of the Year and Finalists) from 1950, 1980, and 2010.
- Some industry write-up (such as PC Magazine’s best new computers for 1979, 1989, and 1999).
- Some policy over time (such as Google’s Privacy Policies)
- Recommendations about what to eat (such as the government’s Nutrition Guidelines. It could be interesting to cross-index the low-fat recommendations from 1980 with today’s ketogenic or Paleo diets.)
- Match your timeline to the subject. For political speeches, you will get the best results if they are at least 50 years apart. For faster-changing items (such as the cellular phone user’s manual), you can probably get away with things 10 years apart. You will have a much easier time making good graphs if you give yourself good raw data to work with.
- Select your desired number of time periods. You must have at least three, and can use as many as you like. (i.e. 2000, 2005, and 2010 would be three time periods.)
- Take your text items for each year and convert them into a text input file.
- Run a Python program to determine the top X word count for each year. You will need to determine how many words you are going to use in your analysis; you should probably have somewhere between 5 and 30.
- You will need to make decisions about stop words.
- Make sure the bulk of your text processing is done in Python, not using the “search/replace” functions in Excel or Word. Part of this class’ skillset is exposure to Python, and this is how you should do it here.
- Merge your Python word count data into an input file for Tableau. You may find it helpful to use Excel or some other tool for this.
- Analyze your data. Emphasis here will be placed on visual analysis and text analysis.
- As part of your analysis, take the top 3 interesting relevant words from your latest time period. (You can use some judgment here; for Amazon, “kindle” would be more interesting than “book” even if “book” had more occurrences.) Trace the trajectory of each of these 3 words over time – for example, at Amazon, the word “kindle” gains tremendously in popularity over time.
- Create a managerial report in Word outlining your findings.
Use what you already know about visualization. Additionally, some Tableau graphs you may find helpful for this sort of analysis include:
- Bump charts – to show changes in rank of items over timehttp://www.tableau.com/learn/tutorials/on-demand/bump-charts
- Packed Bubble Charts – http://onlinehelp.tableau.com/current/pro/desktop/en-us/help.htm#buildexamples_bubbles.html

A successful report will
- Contain a title page and a list of references and pass a plagiarism check in Turnitin
- Begin with a results-filled Executive Summary (half a page to one page). The Executive Summary needs to orient the reader to your company and the analysis you are doing, and give actionable outcomes.
- Be otherwise 5-10 pages in length (I will stop reading after page 10). So if you have 1 title page, 1 list of references, and 1 page of Executive Summary, you could turn in up to 13 pages of stuff.
- Contain reasonable typeface and margins (12-point Times New Roman with 1-inch margins work just fine).
- Follow our Modified APA Formatting. This follows standard APA formatting, with one exception: please integrate your figures within the body of your document. Don’t put them in the Appendix. If you are on page 3 talking about Figure 1, make sure the reader can see Figure 1 on page 3.
- Show mastery of the readings in the class to date
- Showcase your data visualization skills in Tableau, with exactly 5 graphs (4 is not enough, and I will not look at a 6thor further graph). The online help at http://www.tableau.com/learn/tutorials/on-demand/formatting contains formatting tips which will make it look really professional.
- Contain action words in your captions. Captions need to tell the reader what is happening here – something like “Count of Top Three Words at Amazon.com” isn’t helpful. “The word ‘Kindle’ is growing fast, overtakes ‘Paperback’ in 2015” is a better choice.
- Contain a list of your top 3 words, with your reasons for choosing them, and trace their trajectory over time
- Analyze anything else you find interesting
- Integrate your charts with your conclusions
- Give a busy executive a clear path to follow in terms of action items and a “to do” list
Please submit:
- All Python code you used (it’s OK if you simply used or modified the code I have here; just ensure the comments reflect your name and what you did. For example, it should say, “Code initially posted by {First author here}. Updated on XXXXX by YYYYYY to reflect ZZZZ changes.”)
- All .txt text input files you used (I imagine you might have one input file for each year)
- All Excel (or other format) input files you used for Tableau, so I can see how your data shaped up
- Your managerial report (ensure the bibliographic reference include the source data; my report should include a reference to the Amazon.com shareholder letter). Name this file “XXXX-text-analysis” where XXXX is your name.
Grading Rubric:
| Score | Definition |
| 90 – 100 | Exceeds Expectations. Meets all the criteria of the “meets expectations” presentation, and goes beyond in some meaningful way. Code is cleanly written, well commented, and works correctly; code is creatively written and does not pull heavily from the sample code in our class materials. Most stop words are removed; perhaps stemming is done as well (condensing “jump” “jumping” and “jumped” into the same root word.) Capitalization and punctuation are successfully addressed. Text sets are rich and varied, and the trajectory of meaningful keywords is clearly called out in the paper to provide valuable business insight. Covers significantly more time periods or significantly more text than called for. Demonstrates mastery of the Python programming techniques we have covered in class. Uses modified APA formatting: include figures within body of text, not in an Appendix. |
| 80 – 89 | Meets Expectations. The average score at UMUC is 85%, and a submission which meets expectations will earn this score. The computer code here will be written and commented at a reasonable level, and will generally work on most input files. Code may be heavily based off of the example provided in class. Most, but not all, stop words are removed; very little, if any, stemming is done. May or may not change all text to lower case. Paper covers the story in this data, and includes tracing of keyword trajectory over time. The reader comes away with a good idea of what was accomplished and what the major conclusions were. Each graph is labeled with a Figure number, and all APA formatting is met. Uses modified APA formatting: include figures within body of text, not in an Appendix. Page requirements are met. |
| 0 – 79 | Does Not Meet Expectations. The computer code here does not work, or is an exact duplicate of the sample provided in class. The word counts do not match the input files, and we cannot replicate the results. The paper is scattered or disorganized, and does not present the word counts over time. May present word counts in generic bar graphs or pie charts. The graphs used may not be the best way to display the data. There is not a strong storyline, and at the end, the reader will not have a clear idea what was done and what the conclusions are. These papers may have significant proofreading issues or difficulty meeting page limit requirements. Figures may not be labeled, and there is divergence from modified APA formatting. |
Some tips on making this work:
Convert the CEO’s letter to shareholders into a text input file for each year. Here’s how I got it to work:
- For example, let’s say I choose 1997 for Amazon.com. I found CEO Jeff Bezos’ letter here: http://www.sec.gov/Archives/edgar/data/1018724/000119312513151836/d511111dex991.htm and found it contains both his 2013 letter and his 1997 letter.
- I fired up Notepad text editor and had a new file ready
- On the Amazon letter screen, I selected the entire HTML text of his 1997 portion
- On the Notepad window, I did Edit -> Paste
- It pastes just the text into the Notepad window. (It may replace logos with the placeholder LOGO, and you should expect that lines and other graphical items won’t translate over.)
- I saved this as a Notepad file called “1997_LETTER.txt”
- You may encounter a variety of formats and need to do some other translating.
- The basic idea is you need a plain .txt text file here – .pdf or Word files won’t do.
- If your Python program gives you input error messages, try appending text one line at a time to your input file. Sometimes there are nonprinting characters which give you problems.
- If your input continues to have indigestion, you may find it easier to simply retype the CEO letter directly into our text editor. That is just fine.
Run a Python program to determine the top X word count for each year. Here’s how I got it to work:
- Review the Severance textbook, Chapter 9. The “Romeo” code from Chapter 9, and Section 9.4 (advanced text parsing) are key to your success here.
- I borrowed code from Toby Donaldson’s Python QuickStart Guide (location 5347, way in the back). With that as a background, I produced a Python program which will open the input file, count characters, lines, and words, and produce a list of the top 30 words.
- You are welcome to use this program and modify it to suit your needs; if you do so, please just modify the header to reflect that you are the last person to update it
- You are welcome to write your own code if you prefer, based on the Romeo program or from scratch.
- Here’s the Python code:
# Starter Code –
# Based on Toby Donaldson’s Python: Visual QuickStart Guide
# functionprint_file_stats (location 5347)
#
# Modified for UMUC DATA 620 by Carrie Beam
# Last updated: 8/7/15
# Program to open a text file named ‘1997_LETTER.txt’
# This program will give a word count of all the words in the file
# and give the top 30 words.
# It has not been modified to do any stop wording
# Open the input file
s = open(‘1997_LETTER.txt’, ‘r’).read()
# count characters
num_chars = len(s)
# count lines
num_lines = s.count(‘\n’)
words = s.split()
d = {}
for w in words:
if w in d: # seen w before?
d[w] += 1
else:
d[w] = 1
num_words = sum(d[w] for w in d)
lst = [(d[w], w) for w in d]
lst.sort()
lst.reverse()
print(‘Your input file has characters = ‘ + str(num_chars))
print(‘Your input file has num_lines = ‘ + str(num_lines))
print(‘Your input file has num_words = ‘ + str(num_words))
print(‘\n The 30 most frequent words are \n’)
i = 1
for count, word in lst[:30]:
print(‘%2s. %4s %s’ % (i, count, word))
i += 1
1997 LETTER TO SHAREHOLDERS (Reprinted from the 1997 Annual Report)
To our shareholders:
Amazon.com passed many milestones in 1997: by year-end, we had served more than 1.5 million customers, yielding 838% revenue growth to $147.8 million, and extended our market leadership despite aggressive competitive entry.
But this is Day 1 for the Internet and, if we execute well, for Amazon.com. Today, online commerce saves customers money and precious time. Tomorrow, through personalization, online commerce will accelerate the very process of discovery. Amazon.com uses the Internet to create real value for its customers and, by doing so, hopes to create an enduring franchise, even in established and large markets.
We have a window of opportunity as larger players marshal the resources to pursue the online opportunity and as customers, new to purchasing online, are receptive to forming new relationships. The competitive landscape has continued to evolve at a fast pace. Many large players have moved online with credible offerings and have devoted substantial energy and resources to building awareness, traffic, and sales. Our goal is to move quickly to solidify and extend our current position while we begin to pursue the online commerce opportunities in other areas. We see substantial opportunity in the large markets we are targeting. This strategy is not without risk: it requires serious investment and crisp execution against established franchise leaders.
It’s All about the Long Term … (continues from here)
4. Here’s the beginnings of the input text file I used (notice there are no graphic logos or lines):
5. Here’s the output from the Python code (for the whole 1997 letter):
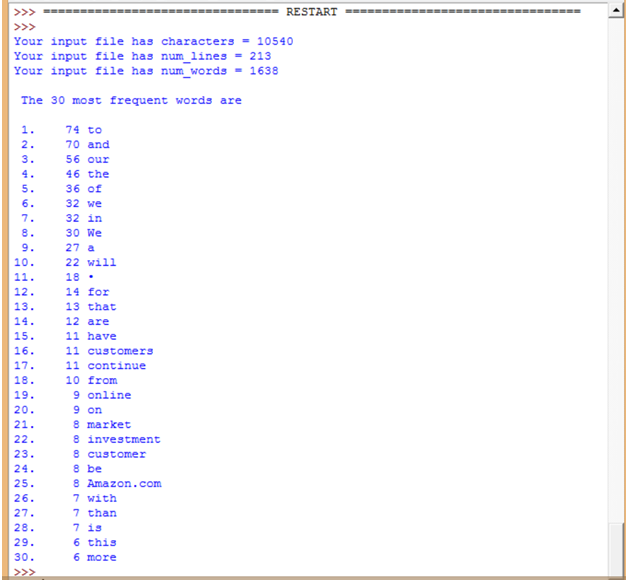
6. Note this output is not quite ready for importation to Tableau.
-
- My program doesn’t have any stop words removed from the text, so they are topping out my list. A stop word is a “junky” word like “a” and “the” which doesn’t really add much to the content of the text, but which occurs pretty frequently. You can get rid of stop words using the Python string. Replace () function. (See the Python documentation and search on “string replace.”)
- I also don’t have any processing of the string to lower case, so “We” and “we” show as two different words here (items #6 and #8 respectively).
- I didn’t take out the bullet points, so they are showing up as item #11. They are probably not valuable information and should be removed one way or another.
- You will need to make your own decisions about what sorts of words/symbols you will remove and about capitalization.
- You will also need to make your own decisions about whether you want to have 30 words at your disposal, or more or fewer.
7. If I were to pull together a data file from what I have here, in Excel to import to Tableau, it might look a little bit like this:
| Rank | Count | Word | Year |
| 1 | 74 | to | 1997 |
| 2 | 70 | and | 1997 |
| 3 | 56 | our | 1997 |
| 4 | 46 | the | 1997 |
| 5 | 36 | of | 1997 |
| 6 | 32 | we | 1997 |
| 7 | 32 | in | 1997 |
| 8 | 30 | We | 1997 |
| 9 | 27 | a | 1997 |
| 10 | 22 | will | 1997 |
… Etc …
8. You are welcome to put together the data in whatever format you feel will best work with Tableau.
Reference ID: #getanswers2001168